
par Emmanuel Chaput chaput@ensica.fr
Si la gestion des fichiers de configuration tels que /etc/passwd ou /etc/hosts est simple sur une machine isolée, elle peut se révéler beaucoup plus problématique sur un réseau comportant un nombre important de stations. Il est en effet difficile, mais important, de garder une cohérence entre les fichiers de configuration des différentes machines. La tache de l'administrateur du système s'avère alors pénible, puisqu'il lui faut mettre à jour autant de fichiers qu'il a de machine sous sa responsabilité, et ce chaque fois qu'une ressource (machine, imprimante ou même utilisateur) est ajoutée, supprimée ou modifiée. Dans de telles conditions, l'administration d'un réseau devient vite pénible, voir impraticable.
Le Network Information Service (ou NIS anciennement connu sous le nom de pages jaunes, ou yellow pages) propose une solution à cette situation problématique. Pour cela, NIS fournit un mécanisme de gestion centralisée des principaux fichiers de configuration d'une machine UNIX. Ce mécanisme fonctionne selon un modèle client-serveur.
Un tel service est particulièrement adapté aux fichiers de configuration communs à tout un ensemble de machines, tels que :
Il reste cependant sans intérêt pour les fichiers plus spécifiques à chaque machine tels que la liste des systèmes de fichiers à monter (1).
Le service NIS fonctionne selon un modèle client-serveur. La figure 1 montre un exemple de configuration d'un ensemble de machines utilisant NIS. Plusieurs serveurs peuvent être actifs simultanément, mais un seul d'entre eux, appelé serveur maître, possède la source des informations. Les autres serveurs (appelé serveurs esclaves), obtiennent une copie des informations en provenance du serveur maître. Un tel mécanisme permet de meilleurs temps de réponse. Les machines utilisant le service NIS pour obtenir les informations sont appelées les clients. De plus, les clients NIS ``choisissant'' leur serveur dynamiquement, un serveur hors service ne bloque que temporairement ses clients si un autre serveur est là pour traiter leurs requêtes. Ainsi la structure de la figure 1 peut évoluer au cours du temps, en fonction de la disponibilité des différents serveurs.
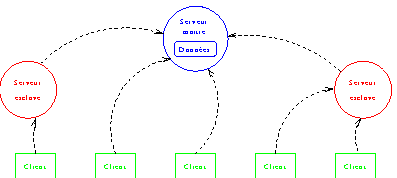
Figure 1:
Architecture client-serveur de NIS.
Un serveur (qu'il soit maître ou esclave) peut être également client du service NIS, et c'est généralement le cas. Ce n'est cependant pas une obligation. Certains serveurs particulièrement ``critiques'' peuvent ne pas utiliser les services NIS, notemment pour la gestion des utilisateurs.
Chaque ensemble de données géré par NIS est stocké dans une table NIS. Une table NIS est composée d'un ensemble de couples ( clef, valeur). Les recherches à l'intérieur d'une table ne peuvent se faire que sur le critère de la clef.
Un domaine NIS est un ensemble de tables NIS, mais l'on désigne souvent, par extension, sous le terme de domaine NIS l'ensemble des machines qui utilisent les mêmes tables. Un domaine est caractérisé par son nom.
Toute information susceptible d'être gérée de façon centralisée au niveau d'un réseau peut être gérée par NIS. Ce dernier permet par défaut de gérer un certain nombre de fichiers.
Le service NIS est ainsi particulièrement bien adapté aux fichiers censés être communs à un réseau de machines, tel que le fichier des mots de passe ( /etc/passwd), celui définissant les noms symboliques des machines ( /etc/hosts) ou encore celui des aliases mail ( /etc/aliases).
NIS, en revanche, n'est, bien entendu, d'aucune utilité pour la gestion des fichiers plus spécifiques aux machines, tels que le fichier des répertoires à monter sur une machine (2) ( /etc/fstab).
Notons également que le service NIS est parfaitement ouvert à la gestion de nouvelles informations. Toute base d'informations pouvant être gérée de façon centralisée peut être traitée simplement par NIS. La seule véritable contrainte sur l'information est qu'elle puisse être stockée sous forme d 'enregistrements ( clef, valeur), chaque valeur pouvant alors être retrouvée en fonction de la clef. Ainsi un annuaire peut être aisément mis en place avec NIS, la clef étant le nom des personnes et la valeur contenant les informations interéssantes (numéro de téléphone, bureau, adresse e-mail, ...).
Si l'information doit pouvoir être accédée par une autre clef (on veut par exemple pouvoir demander à notre annuaire des choses comme `` Qui travaille dans le bureau xxx ?''), il faut alors créer plusieurs tables NIS, chacune contenant la même information indexée par une clef différente. Il faut alors théoriquement se préoccuper de conserver la cohérence des différentes tables entre elles; cependant les tables NIS sont générées automatiquement à partir de fichiers mis à jour par l'administrateur, il est donc tout à fait possible de générer deux tables similaires à partir du même fichier.
Un dernier inconvénient quand à la gestion de bases d'information grâce à NIS est la difficulté de modifier les données. A priori, seul l'administrateur de NIS peut modifier la base de données, et ce uniquement sur la machine qui est le serveur maître. De plus, une telle modification n'est pas ``élémentaire'' dans son principe, puisqu'elle implique une recompilation de la base de données, puis une propagation, via le réseau, de la nouvelle base. On évitera donc de gérer par NIS des bases d'information qui sont, par nature, changeantes, telles qu'un agenda. Si il semble utile de laisser la possibilité aux utilisateurs de modifier une table NIS, on prendra soint de construire les commandes nécessaires (voir par exemple la commande yppasswd pour la table des mots de passe).
La table 1 donne la liste des fichiers traditionnellement gérés par NIS. Ces fichiers peuvent être augmentés, auquel cas le fichier local correspondant reste valable, NIS ne faisant qu'ajouter de nouvelles informations, c'est le cas par exemple du fichier des mots de passe, qui permet de définir des utilisateurs locaux à une machine (3). Mais ces fichiers peuvent également être complètement remplacés par la table leur correspondant, c'est le cas du fichiers des noms de machines, /etc/hosts qui n'est pas consulté si le service NIS est actif.
| Nom du fichier | Augmenté Remplacé | Type d'information |
| /etc/aliases | A | Les aliases utilisés pour le mail |
| /etc/bootparams | A | Informations pour le boot des stations sans disque |
| /etc/ethers | R | Correspondance adresses MAC - adresses Internet |
| /etc/group | A | Liste des groupes d'utilisateurs |
| /etc/hosts | R | Correspondance adresses Internet - noms |
/etc/netgroup
| N
| Groupes réseau (introduit par NIS)
| |
| /etc/netmasks | R | Masques réseau |
| /etc/networks | R | Adresses réseau |
| /etc/passwd | A | Définition des utilisateurs |
| /etc/protocols | R | Noms des protocoles réseau |
| /etc/rpc | R | Définition des RPC |
| /etc/services | R | Noms et ports des services réseau |
Voila pour ce qui est des principes généraux de NIS. Nous verrons dans un prochain numéro de go@elfix comment mettre tout cela en place. Une version de NIS est évidemment disponible sous Linux, de même que NYS, qui est un implémentation de NIS et NIS+, le "successeur" de NIS. On peut trouver NYS par exemple à l'URL ftp://ftp.ibp.fr/pub2/linux/nys/.
(1)
La gestion de ce dernier peut cependant être améliorée grâce à l'automount.
(2)
Encore que cet exemple soit mal cjoisi, puisque l'automount permet justement de profiter de NIS au niveau du montage.
(3)
Le super utilisateur, particulièrement, ne doit pas être définit dans la table NIS, pour des raisons évidentes de sécurité.